Build a Modern Scalable System - Basics
This article is Part 1 in a 7-Part Series.
- Part 1 - This Article
- Part 2 - Build a Modern Scalable System - Runtime Challenges
- Part 3 - Build a Modern Scalable System - Practice on Embedded Router Mode w/ Spring-Cloud
- Part 4 - Build a Modern Scalable System - Practice on Gateway Mode For Mixed-Languages Case
- Part 5 - Build a Modern Scalable System - Practice on Service Mesh Mode with Consul and Nomad
- Part 6 - Build a Modern Scalable System - Practice on Service Mesh Mode with Consul, Nomad and Envoy
- Part 7 - Build a Modern Scalable System - Presentation of Runtime and Data Layers Challenges(in Chinese)
Table of Contents
- Table of Contents
- Architecture Challenges
- Application Architectures
- Cloud-Native(MSA based) platform
- Wrapping up
In the past a couple of years, I spent most of my time on the platform architecture design in a startups. That is a quite different experience than my earlier workarea. We initialed the first project by four developers at the beginning, and build up everything from scratch, including DevOps and platform infrastructure. Many interesting things happened during this period. The question I asked the most by my team/myself is what is best technical architecture to build a scalable system in a startups in each growth phases. I'd like to jot down a series posts on this topic, including some hands-on practices(fully automated and easy to run) for demonstrations.
Firstly, let's take a step back to have a look at the architecture challenges, why we care about scalalbility in software, what does scalability model say, what is typical application architectures for past, present and near-future.
Architecture Challenges
In earlier post, we talked a little bit about hardware and software trends, the free lunch supplied by hardware eventually will end someday. As a response to hitting the ceiling in hardware field. Today, in order to build a system with highly scalability, reliability and availability, the software architecture need to empower the capability of horizontal-scaling. However, realistically, for a complex and evolving application, tranditional architectures encounters many challenges, including:
- Slower team iteration. Application keep growing to huge codebase, either compiling or testing take too long time before pack/deploy a newer build driver.
- Database grows too large.
- Programming language constrained. To avoid disrupting the others components, programmer cann't pick up a more suitable technical stack for the new feature development.
- Scale can not be isloated in a fine-grained scope. Application can be horizontally scaled, it has to request sufficient CPU, memory, network and disk I/O resources based on the entire large application capacity and deploy huge chunk of code over and over again on multiple allocated runners, although the performance bottleneck usually comes from a piece of execution points. An entire application clone is not cost-effective.
- Throubleshooting become harder and harder due to the keeping increasing codebase.
These problems eventually restrict/prevent a fast, reliable and cost-effective horizontal-scaling. How to address this? Strategically, it sounds like quite straightforward. We need to pursue to split the huge codebase into smaller individual components, each component encapsulates specific business functionality, theoretically, the smaller size component could offer the benefits to reach the new levels of scale(fine-grained), agility(team iteration) and fully utilization on hardware resources. This is similar as the case of filling in a bottle with stone, smaller stone or sand, which one can fully utilize the bottle inner space? Of course, the sand.

My apologize that I forgot where I found the picture above, just remember the feeling when I happened to see it :-) . It is so suitable to put here. So far, I can't find the owner of the pic by google, if you know, please let me know. Thanks.
Obviously, we can take benefits by breaking down a coarse-grained service into smaller pieces. But there is no real free lunch, on the way to that, we need to resolve many architectural and operational challenges, includes how to ensure each component should be implmented in a highly autonomy fashion, that means in whole software lifecycle of a component, it should be independent to other components. In the meanwhile, the overall architecture should provides the capability of components orchestration, ensure they work together seamlessly just like they are running in a single process space. To achieve this, both runtime and data layers need significant technical innovation.(more details will be covered on them in upcoming posts in this series).
With the background requirements mentioned above, Microservices Architecture(MSA) bring up after SOA, and provide an architectural design pattern to guide programmers developing a modern application as a suite of small autonomy services, each running in its own process, own its database, implemented by appropriate technical stack, and communicating with lightweight mechanisms, such as HTTP, gRPC API. It grows increasingly in recent years and soon become an popular approach to build cloud-native applictions. Indeed, the rapidly growing of the cloud confirms that more and more applications either being built upon cloud-native technology or start to do the cloud transformation.
The MSA was not created from scratch, it actually is an extension/growth based on SOA technology. So it is necessary to take a look at the history of architectures and get a big picture about architecture evolution.
Application Architectures
Scalability as one of distributed system design principles become more and more important in modern software architecture design.
Scalability: Performance, Responsiveness, Efficiency, that means the software adapts well to increasing data or number of users. It is a non-functional property of a system that describes the ability to appropriately handle increasing (and decreasing) workloads. A system is described as scalable, if it will remain effective when there is a significant increase in the number of resources and the number of users.Two typical apporaches for a distributed system to support lager physical resources:
Vertical-scaling: Adding more resources to individual server. This approach heavily replies on hardware development.Horizontal-scaling: Add more nodes.Besides
scalability, below are some other key principles that influnce the design of large-scale distributed system:
- Availability: Fault Tolerance, Robustness, Resilience, Disaster Recovery, means the software is able to run and available most of the time, in the meanwhile, the software is resistant to and able to recover from comonent failure.
- Reliability: The software is able to perform a required function under stated conditions for a specified period of time. A system needs to be reliable, such that a request for data will consistently return the same data.
- Extensibility: New capabilities can be added to the software without major changes to the underlying architecture.
- Modularity: the resulting software comprises well defined, independent components which leads to better maintainability.
- Cost: Cost is an important factor and include hardware and software costs.

Scalability model
The Scale Cube invented a very insightful scalability model for building resilient and scalable architectures.
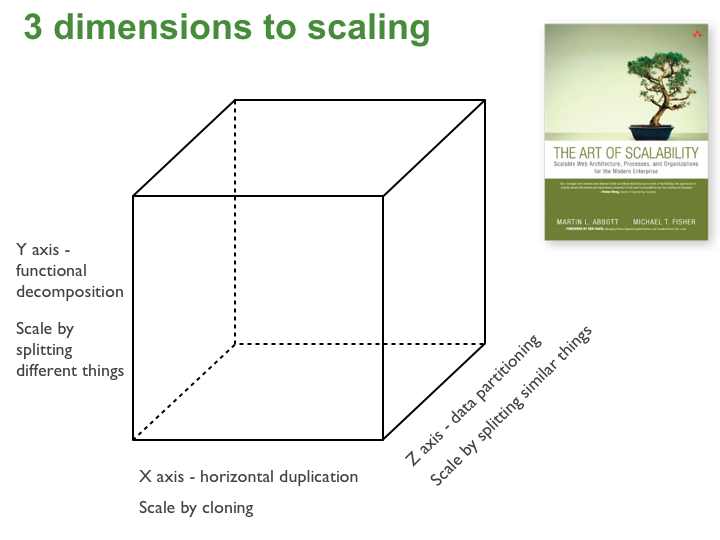
The Scale Cube (a.k.a “AKF Scale Cube” or “AKF Cube”) is comprised of an 3 axes: X-axis, Y-axis, and Z-axis.
- Horizontal Duplication and Cloning (
X-axis)From microservices.io
X-axisscaling consists of running multiple copies of an application behind a load balancer. If there are N copies then each copy handles 1/N of the load. This is a simple, commonly used approach of scaling an application. - Functional Decomposition and Segmentation - SOA and Microservices (
Y-axis)From microservices.io
Y-axisscaling splits the application into multiple, different services. Each service is responsible for one or more closely related functions. - Horizontal Data Partitioning - Shards (
Z-axis)From microservices.io
When using
Z-axisscaling each server runs an identical copy of the code. In this respect, it’s similar toX-axisscaling. The big difference is that each server is responsible for only a subset of the data. Some component of the system is responsible for routing each request to the appropriate server.Z-axisscaling splits are commonly used to scale databases. Data is partitioned (a.k.a. sharded) across a set of servers based on an attribute of each record.Something need to clarify is, the
Z-axisscaling splits database specific to a horizontal approach. It defines a routing criteria based on entity type or an attribute in then entity, then the request will be routed to appropriate database or table accordingly. For a cross-partitions query request, the router send the request to all of partitions, a query aggregator will receive and combines all of results from each of them. In this way, we actually partition the rows between the partitioned databases or tables. Generally, we want to achieve this with a transparent approach to upper business logic layers. For example, in Java, we can do this via-
[1] Instrument DB-Driver(e.g: JDBC library) and inject a DB/Table router there. Sharding logic hosted in database driver.
e.g: sharding-jdbc
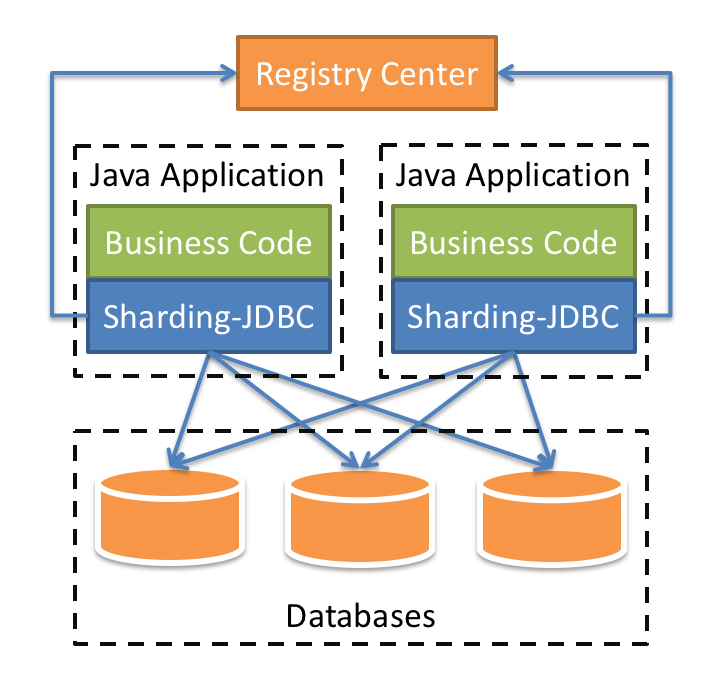
-
[2] Enable a database proxy between logic code and target databases, have the proxy do the routing. Sharding by DB connect proxy,
e.g: sharding-proxy
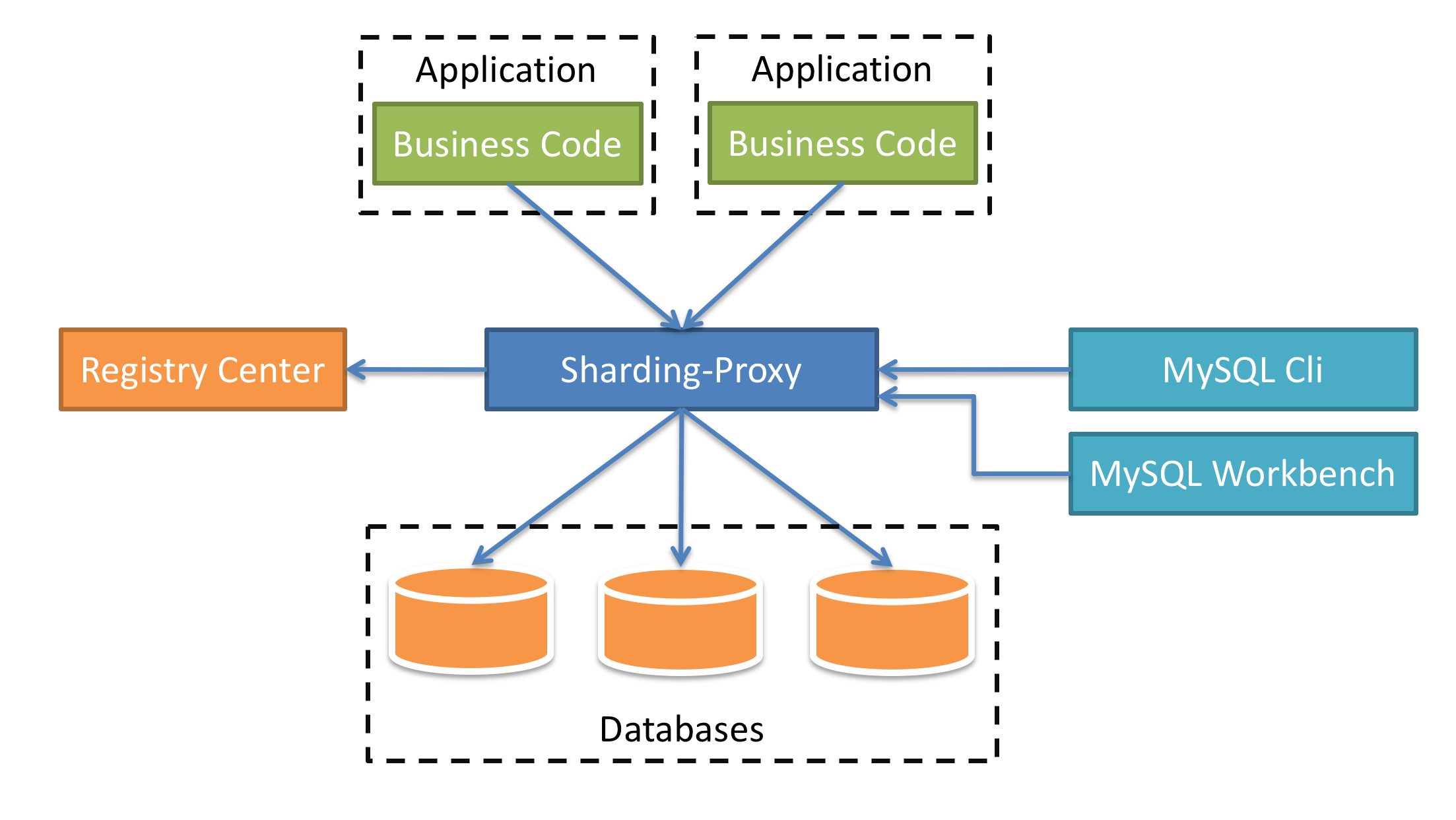
IMO, in either way,
Z-axisscaling actually does not offer to reduce the application implementation complexity(we can argue). Do a transformation from monolith to MSA, we usually need vertical splits on the data model and database to satisfy the database-per-service principle firstly. That need to be done byY-axisscaling with microservices data model design methodology(e.g:Domain Driven Design), I will introduce this topic in later post for data challenge part. -
PS: If you are interested in Scale Cube model, please refer to The book The Art Of Scalability and excellent microservices.io article for more details.
Architectures Overview
Broadly speaking, we have three kinds of architectures for enterpise application:
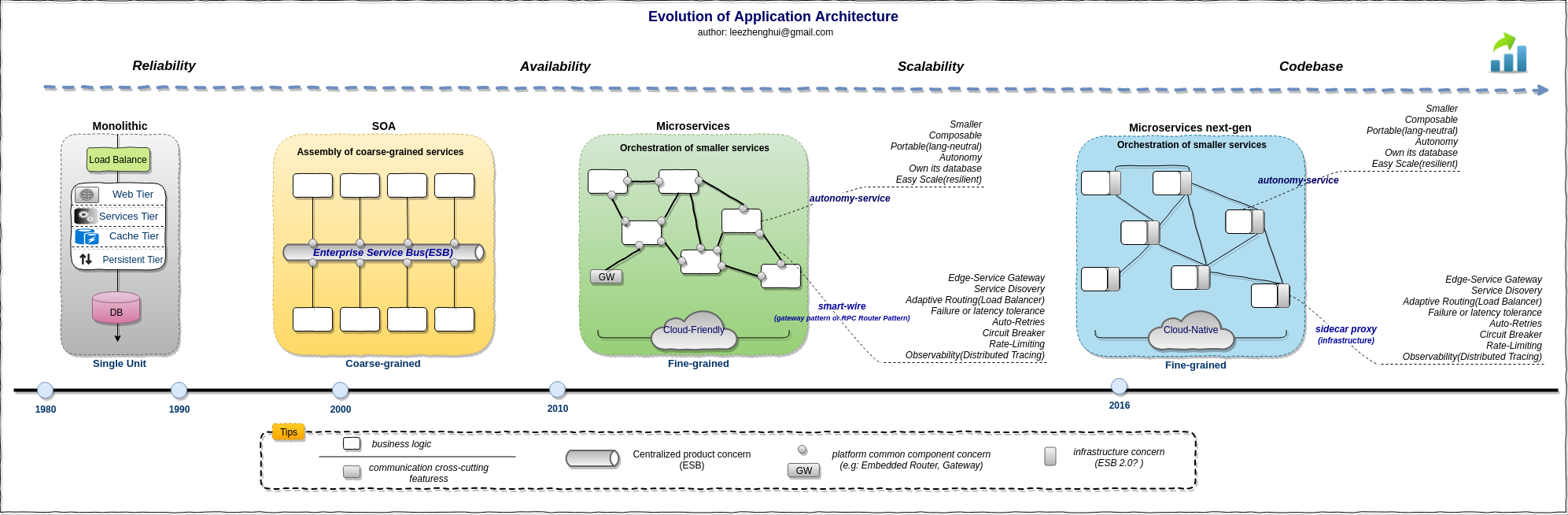
Monolith
The monolithic architecture makes sense for simple and lightweight applications. Even today, it is still applicable. Monolithic architecture can be horizontally scaled via X-axis. It usually the same data models/data store for all components running in a single process. The Z-axis scaling is also applicable but sometimes the effect is limited by lack of Y-axis scaling. In the monolith view of the world, the inter-communication for subsystems is pretty easy, as it was an in-process space function call. There are not many upstream dependencies. We usually hardcode the configuration into a property file, put a load balancer in front of it and we scale horizontally by adding more monoliths.
Monolith has a number of benefits, When the application in smaller codebase phase:
-
Easy to build and start
-
Easy to test, especially for end2end test. Having all of components running together in a single process space.
-
Easy to integrate into IDE for debugging. Sharing the same tech-stack, codebase contained by single project.
-
Simple deployment(not need orchestration)
With the codebase growing, some drawbacks will meet:
-
Difficult for modularization
-
Too much frameworks inside the application, long learning curve for new developers
-
Slower team iteration
-
Slower innovation as all of components share a similar tech-stack, different to do the tech-stack upgrade wihtin an isolated scope.
-
Hard to do scale in a fine-grained scope
-
Slower deployment
Please keep in mind, the drawbacks for monolith come out when the codebase grows to huge size, sometimes, this definitely is not the major concern for a startup project. IMHO, If your application is still in baby phase or working well, I do not suggest you to do the changes, as fulfill business requirements and settle down the business model is the first class thing to hande in a startup, adopting microservices will offer very little benefit but could take much of time/effort from your team.
SOA
I have ever worked on SOA/ESB fields for quite a long time, that experience is really impressive. Our SOA product provides a standard way to encapsulate our implementation into component, we can declare a component by interface, and decoupled with it's implemnetation, the implementation could be any lanaguages, like: Java, MFC(Mediation Flow Component, one of declare language for ESB), BPEL, BPMN and Script. It also supports different interaction style(sync, async oneway, deferred-response and callback) as well rich QoSs, in the meanwhile, easy to expose as service via various transport/communication protocols(e.g: Corba, JMS, Restful, JAX-RPC, JAX-WS, TCP, MQ, JCA etc). This much reduce the complexity to build up a distrubted system. The ESB and BPM ride on the SOA core and build up their upper stacks. All the things looks perfect.
SOA corresponds the Y-axis scaling to help enterpise application achieve scalability. It eventually get to ESB pattern with ESB product. The ESB product take over most of technical challenges as a centralized Bus, including inter-communication challenges between services invocation, data format/protocol transformations, logging, routing, some advanced features also being considered and covered by ESB product, like workflow, UoW(Unit of Work which is two-phase-commit based) and compansation handling(BPMN or BPEL), etc. Apparently, ESB bring much benefits, especially simplify the service(provider and consumer) design/implmentation, hide the most hard parts in the ESB. But the drawbacks is, the centralized ESB product take too much capabilities, the worse thing is it contains not only non-functional features but also heavy business logic, soon or later it will grow up to an other new monolith, which is centralized and not easy to scale out. The tranditional ESB product finally become the ceiling of the SOA which impact SOA going further on the way of Y-axis scaling. In Z-axis scaling of the Scale Cube, SOA spec does not deal with database design for services, so the data partition still be a horizontal scaling, no much difference than monolith.
MSA & MSA-ng
It is a pity that SOA did not exploit Y-axis scaling of the Scale Cube extremely. The programmers see this problem and bring up MSA. MSA grow based on SOA.
From pure techincal point of view, service definition in MSA extends service concept in SOA, but add below properties/restrictions:
- Service should be fine-grained, using the lightweight communication protocol is highly recommended, e.g: HTTP, gRPC, etc.
- Service should be highly autonomy. The lifecycle management(including: plan, definition, development, test, deployment, operations and sunsetting) for a service should be indepenent to other services.
- Service can fully control its tech-stack.
- Service own its database, it is forbidden to share database/data-model between services.
- Service is smaller, the testing and building time could not be too long which impact continuous delivery agility.
- The interaction between the services should be connected by "smart wire", means support service-discovery, adaptive-routing(load balance), failure/latency tolerance, auto-retries, circuit-breaker, rate-limiting, observability(distributed tracing), etc.
- Edge service(API) need involve a gateway pattern, but the gateway should contain only non-functional functionalities.
- The micro-services also give suggestion on the team size, the "two-pizza" team rule implies team growing big will bring much communication efforts, which will finally slow down the development and hurt the efficiency.
What is the biggest difference between SOA and MSA? IMO, "MSA make the magic in Top-Down fashion"(from business model to technical model), but SOA is likely playing the game in Bottom-Up fashion(from technical model to business model). Frankly speaking, in a long time, I did not pay attention on this difference, but when I try to figure out why MSA can make a smaller and autonomy service, I realized I must have missed something here… Yes, Top-Down mode can break down a system into highly decoupled&autonomy smaller pieces via DDD(Domain Driven Design) methodology, in this way, we can statisfy service-per-database principle and make the servie autonomy.(BTW, Eric_Evans published his book Domain-Driven Design: Tackling Complexity in the Heart of Software was at 2004, but seems it is becoming popular with MSA). On the contrary, use the "bottom-up", we only can get the coarse-grained service, these services may (paritial)share with same data model, could not be totally decoupled and not autonomy. Sharing the same data model among different servcies will introduce more complexities in data consistency, this is one of reason for SOA pick up a centralized ESB product which can provide an UoW(Unit of Work, e.g: two-phase-commit) capability across service communication boundaries to guarantee data consistency.
From Pat Helland
"Two-phase commit is the anti-availability protocol."
The MSA is a better choice for complex, evolving applications, and tranditional monolith does not scale anymore. MSA is a exploiting in Y-axis scaling. To satisfy the autonomy and database-per-service principle, A vertical splits on database in the entire system should be a prerequisite. Of course, Z-axis scaling is also applicable on the vertically splitted data model/store.
The benefits of MSA:
- Better agility
- Easy scale
- Easy to add new feature due to a lightweight codebase
- Short learning curve for new developer
- Programming lanauge neutral, easy to adopt to new tech-stack
The drawbacks are:
- Complex infrastructure support
- Deployment is faster, but become complex, it heavliy replies on the cooperations from DevOps, including: CI/CD, orchestration(e.g: traffic control part), etc
- Harder to test, especially, an end2end testing
- Data consistency challenge
To implement a microservices architecture, we need to resolve both runtime and data challenges.
-
Runtime part
- the challenges including cross-cutting concerns for service intercommunication as well as the problems in opertional layer:
- Service registry
- Naming Service(using service name to present an service endpoint address)
- Load Balancer
- Resiliency features(retries/failure or latency tolerance/circuit breaker)
- Distributed tracing
- Aggregated logging
- Traffic Shapping
- etc
-
There are three typical reference architecture modes in MSA to resolve above problems.
-
Gateway Mode
In this pattern, application relies on gateway(public and/or private) for the service communications. Logically, we still have a centralized point in the topology, event that point is easy for horizontal-scaling.
-
Embedded Router Mode
In this pattern, application relies on a embedded router(commonly, delivered as RPC framework) for the resolution, e.g: in java, spring-cloud and relevant plugins features, in golang, go-micro, etc. Usually, it is programming lanauge specific.
-
Service Mesh Mode
Today, MSA is on the way to Service Mesh, service mesh deliver an exciting solution in MSA. In the diagram above, I mark it as
microservices-ng. Not like the other patterns, service mesh puts the solution implemention down to a lower infrastructure layer, this part of work is totally decoupled from business logic code and programming-language-neutral. From conceptual perspective, I am not sure whether we can call itESB 2.0, It delivered similar features around servie communication, but in a totally different way, means NOT like ESB product in SOA, servie mesh is a part of infrastructure layer feature, attach to each service via sidecar pattern, work in a decentralized mannder and focus on cross-cutting concerns of service intercommunications without any business logic involved. I will elaborate more details in my next post regarding runtime part challenges in this series.
-
- the challenges including cross-cutting concerns for service intercommunication as well as the problems in opertional layer:
-
Data part, the challenges mainly include:
-
Data model vertical splits(Database-per-service): Domain driven design
-
Write challenge: Consistency problem
-
Read challenge: Cross-service query problem
More details will be covered in upcoming post in this series.
-
Cloud-Native(MSA based) platform
Shape of a cloud-native platform
Below is a bird's-eye components architecture overview for a cloud-native platform, also includes some of SaaS features.
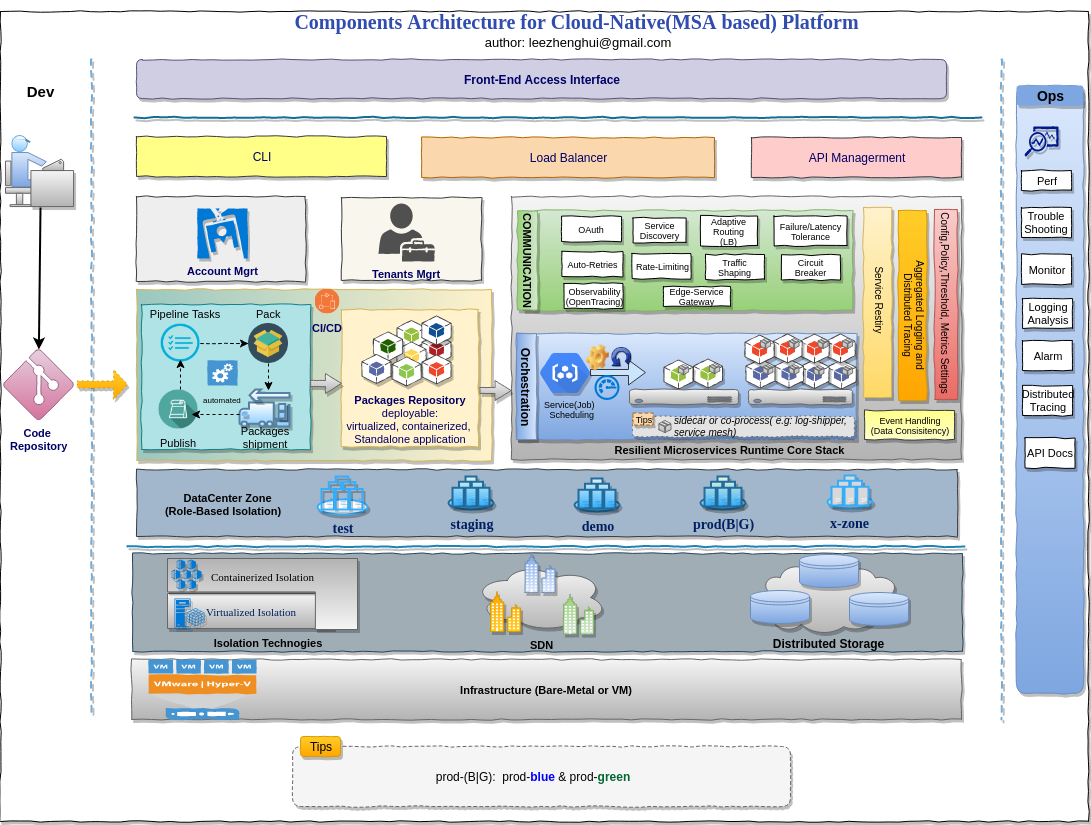
Layers architecture for a cloud-native platform
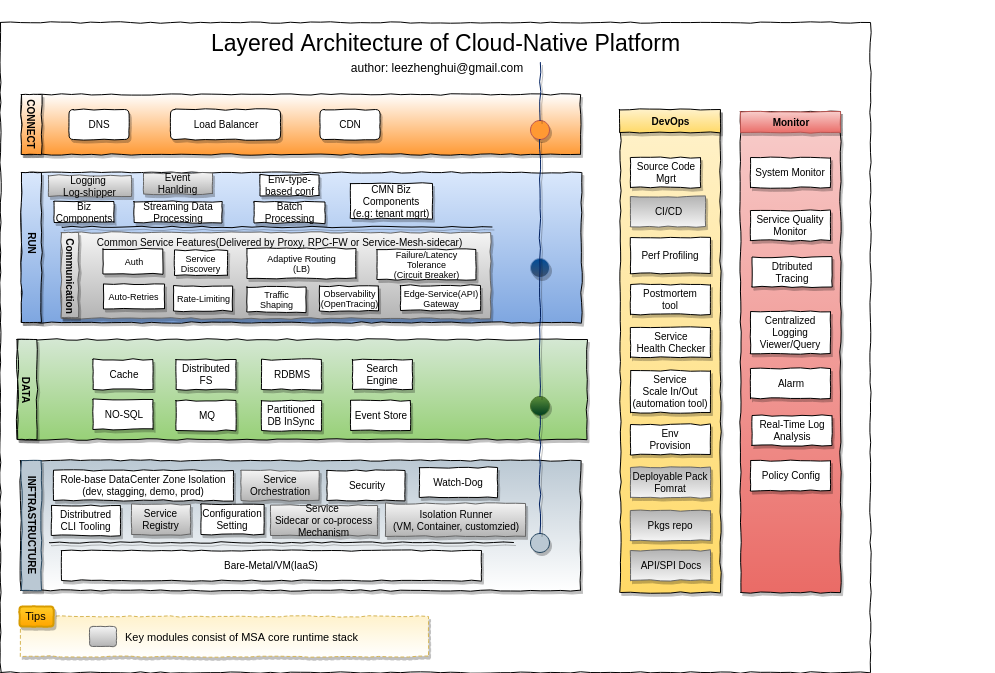
DevOps Pipeline
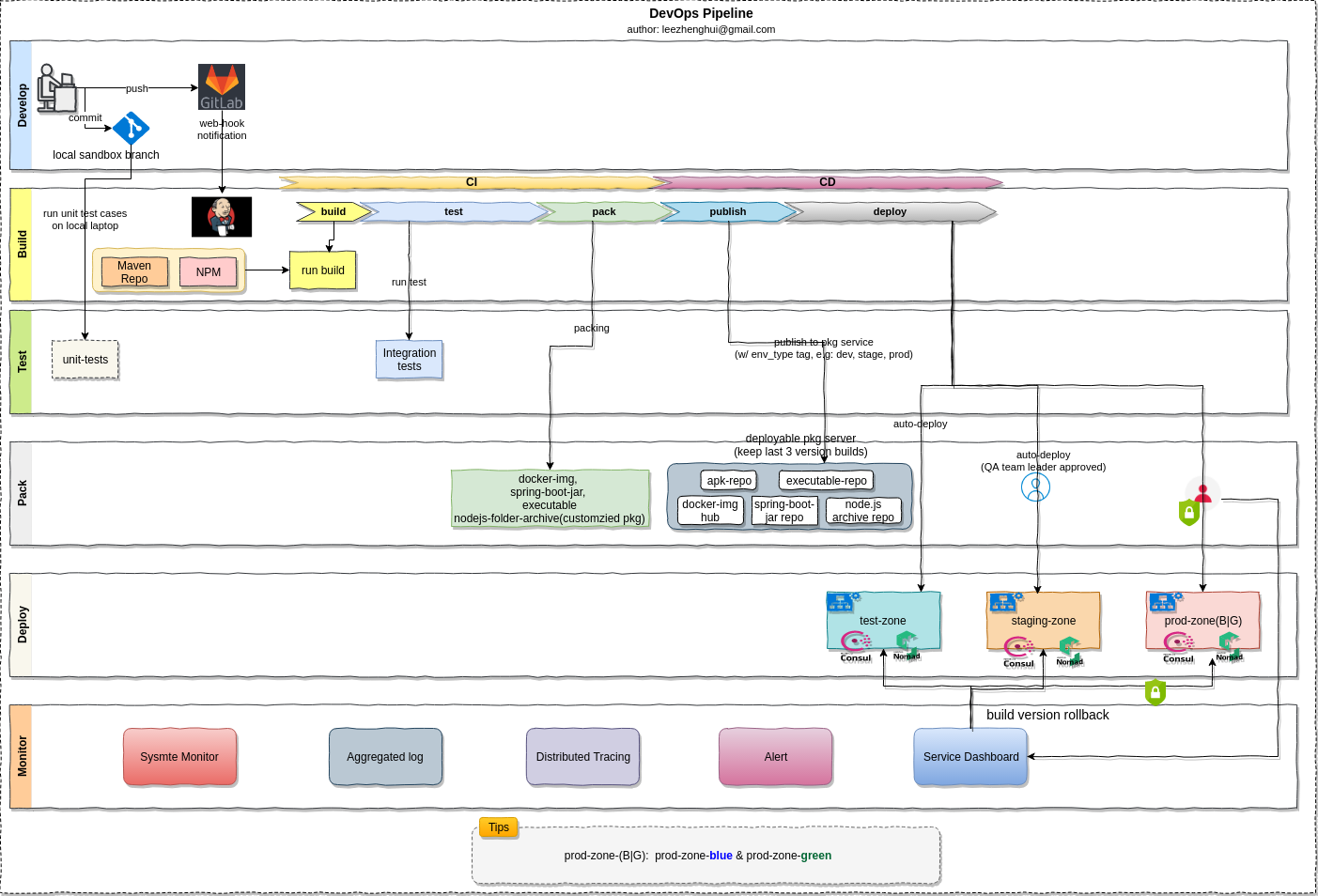
Code checkin process
MSA gives us the suggestion on the team size, the "two-pizza" team rule implies team growing big will bring much communication efforts, which will finally slow down the development and hurt the efficiency.
We follow this rule and strictly control each service size as well as team size, we do the code checkin process as below and it works well on a bi-weekly interation.
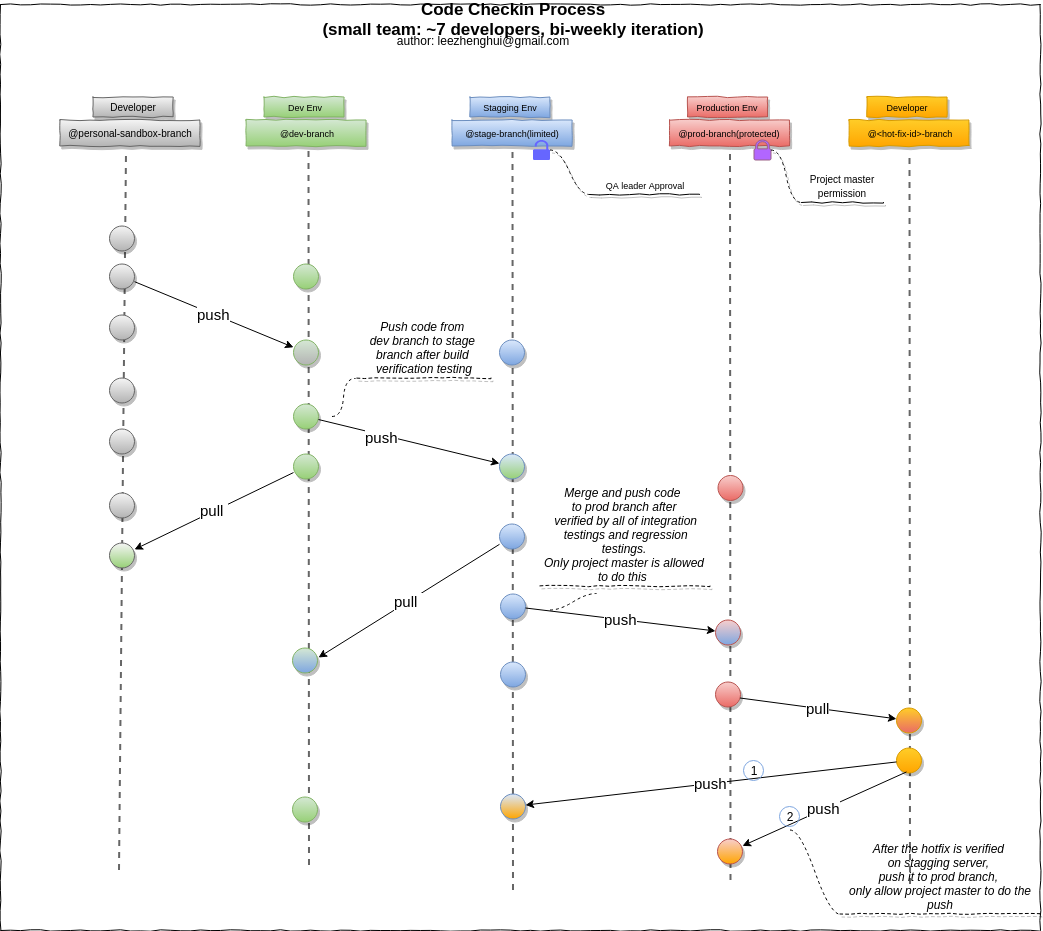
Can go with MSA on a new project?
To answer the question, you need to ask yourself two questions?
-
Is the project has a clear and settled business model?
-
How many resources you want to invest to this project at the beginning phase(usually for a quick business verification)?
If answer to question-1 is no, or you can't invest enough resources to support a MSA relevant infrastructure and opertional layers work, I'd like you go with Monolith. otherwise, pick up MSA please.
Per my personal experiences, many B2C business requirements in our company come without a clear business model, business guys want to figure out the valuable parts and settle down the business models via quick iterations. So at the beginning, We can't completely identify the context boundaries among the components via DDD methodology, in the meanwhile, we are asked to make a quick delivery for business result verification with less resources investment. In this kind of case, it is more suitable to go with Monolith. But keep in mind following below principles will make it easier when you want to move to MSA shortly.
-
Define well-formed API signature, e.g: for Restful API, make sure using reasonable domain name design, dynamic and static resources segregation can be explicitly reflected by url pattern, clear versioning tag, sub-module-awared context-root definition, and so on.
-
If the scenario can accept an eventually consistency in persistence layer, try to avoid using 2PC(two-phase-commit) based distributed transaction, indeed, leverage event-driven design to achieve data consistency requirement. Regarding the data consistent approaches in MSA, I will elaborate more details in the data challenge part in upcoming post.
Wrapping up
So far, we walk through the scalability model, typical application archiectures, roughly explanations for each architectures and finally give my answer to the question of can go with MSA on my new project. In a nutshell, MSA is not a silver bullet for all of architecture challenges. But it does can empower your team to reach new levels of scale and agility.
In next post, let's explore the runtime challenges in MSA, and what aspects we need to consider to make a decision of architecture mode for MSA.
This article is Part 1 in a 7-Part Series.
- Part 1 - This Article
- Part 2 - Build a Modern Scalable System - Runtime Challenges
- Part 3 - Build a Modern Scalable System - Practice on Embedded Router Mode w/ Spring-Cloud
- Part 4 - Build a Modern Scalable System - Practice on Gateway Mode For Mixed-Languages Case
- Part 5 - Build a Modern Scalable System - Practice on Service Mesh Mode with Consul and Nomad
- Part 6 - Build a Modern Scalable System - Practice on Service Mesh Mode with Consul, Nomad and Envoy
- Part 7 - Build a Modern Scalable System - Presentation of Runtime and Data Layers Challenges(in Chinese)