Boost I/O Strategy In Web Server - Motivation
Published:
by
Zhenghui Lee
![]()
- Categories:
- io-strategy 3
This article is Part 1 in a 3-Part Series.
- Part 1 - This Article
- Part 2 - Boost I/O Strategy - Dive into Libev and Libeio
- Part 3 - Boost I/O Strategy - The Internals of Libuvc
Table of Contents
- Table of Contents
- Motivation
- Hardware Trends
- Software Architecture Trend
- Application Trend
- Wrapping Up:
The web-based application have become increasingly popular, in large part due to the rise of cloud and micro-services architecture. More and more API/auto-workflow/user-centric services are either built upon the naturally cloud technology or in the transitional period of on-premises toward cloud-native. Working on a web server software programming, a significant technical challenge is to enable web server with high scalability, concurrency and throughput. To achieve this, I/O is important, because it is slow(why? let's take a walk across the I/O landscape later to get the answer). In order to avoid I/O speed limitting system performance, we have to look for an appropriate I/O strategy to make sure the web server to handles a large number of connections simultaneously with a high throughput, in the meanwhile, the computer resources are fully/efficiently utilized. This topic actually has been weighing on my mind for quite a long time, until now couldn't find enough time to invest. This article is my first blog post in the series where I'll attempt to jot down a series articles on this topic, which came cross with my earlier reading, investigations and experiences as a future reference for me and any one who come across to this post.
In this series articles, we start off a introduction on the background/motivation of this topic, which include a brief introduce of hardware trends, those lead us to think about what software pattern and I/O strategy is good for server performance and scalability, I also extend the topic a little bit to introduce the classic/typical software architectures, as these are the fundamental in software layer to bring things up from theory to practice. In later posts, we will recap c10k problem and then walk throught the markable I/O strategies (following the way lighted by c10k, a little bit older article, but still influencing) achieved in the evolution of high scalability network server, and explore these I/O design patterns and PM(stands for Programming Model) via looking into some good frameworks and(or) playing with some simple samples for the PoC (stands for proof-of-concept).
With that in mind, the discussion center around UNIX-Like systems, in particular to LINUX, WINDOWS may be mentioned a little, however, all of PoC samples only guarantee to run on LINUX.
Motivation
From software perspective, we want to accomplish highly scalability and high concurrency goal in our application, in the meanwhile, ensure the overall system components utilizes the increased system hardware capabilities to the fullest. In modern applications, It is turned out that the I/O strategy design has become one of most important part in web server infrastructure to achieve highly scalability/concurrency. Why? Two principles can enlighen us on this problem: hardware trends and modern application trends, and the architecture trend can guide us and provide the possibility to settle down a practical implementation to overcome the problem.
Scalabilityis a non-functional property of a system that describes the ability to appropriately handle increasing (and decreasing) workloads. A system is described as scalable, if it will remain effective when there is a significant increase in the number of resources and the number of usersConcurrencyis a property of a system representing the fact that multiple activities can be executed at the same time.
Hardware Trends
Before looking into software part, let's take one step back and a look at hardware, the trend of increasing in computing power in the past couple decades has been following Moore's Law.
Moore's law is the observation that the number of transistors in a dense integrated circuit doubles approximately every two years.
CPU Trend
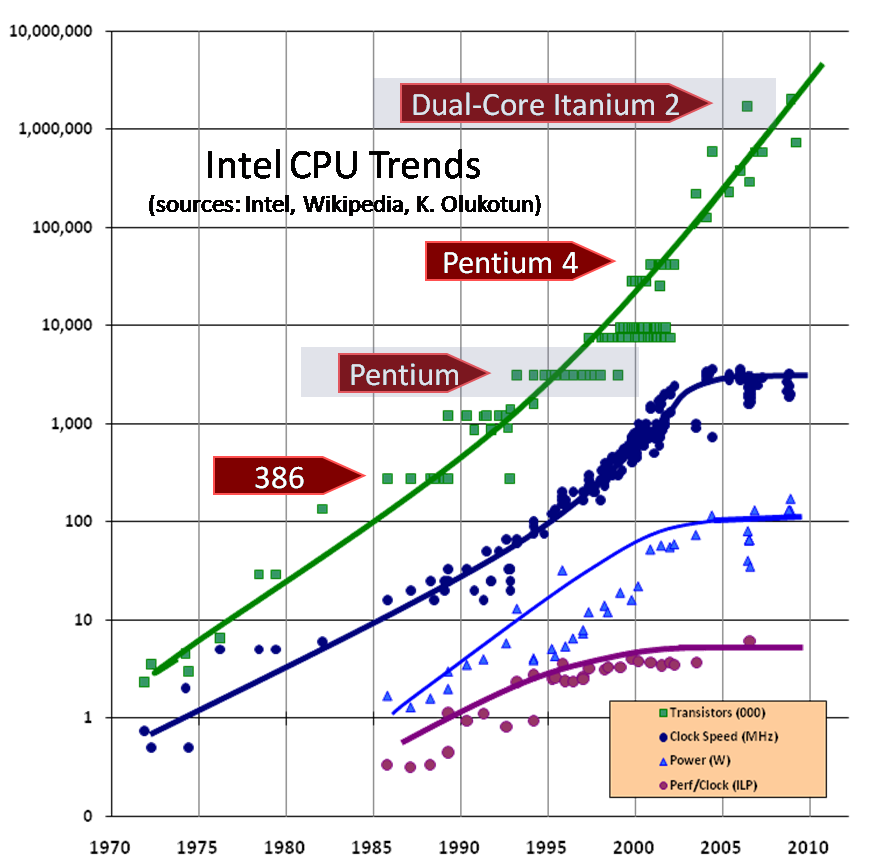 Image credit: (Herb Sutter Dr. Dobb’s Journal, March 2005)
Image credit: (Herb Sutter Dr. Dobb’s Journal, March 2005)
The trends in CPU(refer to Herb Sutter Dr. Dobb’s Journal, March 2005 for more details):
-
Transistor count is truely doubling every 2 years, at least for now.
-
The clock-speed in CPU run in a different story, indeed, the progress of microprocessors has saturated in terms of clock cycles due to physical constraints

It has become harder and harder to exploit higher clock speeds due to not just one but several physical issues, notably heat (too much of it and too hard to dissipate), power consumption (too high), and current leakage problems.
But who consume the power and generate heat? Today, almost all of consumer electronic are built with CMOS logic, CMOS stands for Complementary Metal Oxide Semiconductor. As the complementary part in the name implied, each logic element inside the CPU is implemented with a pair of transistors, one switch on, and another switch off. Stay in the state, there is no current flow, but during the transition of state switching(from on to off, or from off to on), the current flows over the transistors from source to drain. As a result, the power consumption and heat dissipation is directly affected by the count of the transitions per second, that is cpu clock cycle speed.
below is a simplest
NOT logic gate, If the input, A, is high, then the output, Q, will be low, and vice versa
Heat dissipate is quite important for CPU, below the warning level, it will damage the CPU.
-
The Moore's law still works in the near-term future to gain performance growth, but it gain this by a different way, the drivers are
Hyperthreading,MulticoreandCache.
Hyperthreading(intel calls it hyper threading, also a.k.a simultaneous multithreading), allows a single core to execute multiple instruction streams in parallel with the addition of a modest amount of hardware.
From CPU perspective, despite it is not getting faster, they are getting wider, the Moore's law is still not over. In contrast, the I/O does not keep up with Moore's law.
Disk I/O Trend
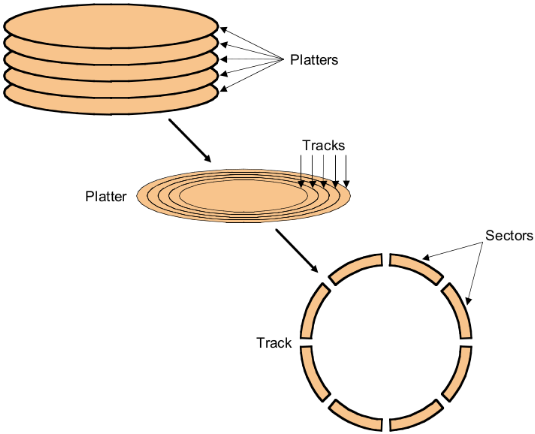 Image credit: (Components of the Virtual Memory System)
Image credit: (Components of the Virtual Memory System)
The HDD speed saturated in the physical constraints:
- Data is stored on double-sided magnetic disks called platters.
- Each platter is arranged like a record, with many concentric tracks.
- Tracks are further divided into individual sectors, which are the basic unit of data transfer.
- Each surface has a read/write head like the arm on a record player, but all the heads are connected and move together.
Accessing a sector on a track on a hard disk takes a lot of time, manufacturers often report average seek times of 8-10ms, these times average the time to seek from any track to any other track. In practice, seek times are often much better, For example, if the head is already on or near the desired track, then seek time is much smaller. In other words, locality is important! Actual average seek times are often just 2-3ms.
It is obviously the speed of HDD is not affected by the transistors desnisty, so it is out control of Moore's law. But flash is resolving this just in time.
Netowrk I/O Trend
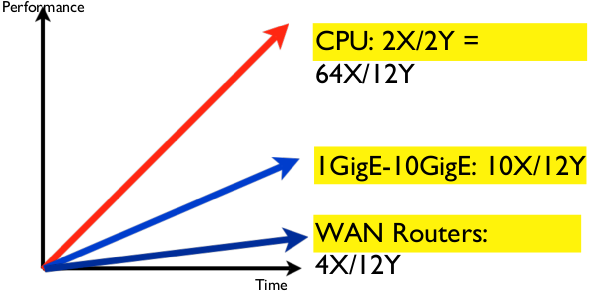
Image credit: Andreas Bechtolsheim Arista Networks Inc
The problems are:
- Moore’s Law applies to transistors density, not speed. Transistor count is doubling every 2 years, but transistor speed is only increasing slowly.
- Number of IO pins per package basically fixed, which is limited by die area and package technology, only improvement is increased I/O speed.
- Bandwidth ultimately limited by I/O Capability, Throughput per chip = # IO Pins * Speed/IO, no matter how many transistors are on-chip
Besides above problems, the Pipefile and network I/O have an other characteristic which also need our attentions. Not like regular file I/O(e.g: disk I/O), the network I/O latency not only comes from the low level hardware, it also impact much by the interaction style, we can not assume the data is generated and ready for read when we perform a read operation, actually, we are even not able to estimate when the data will be generated, it absolutely decided by the data producer side.
Software Architecture Trend
Vertical Scaling
In the early time, hardware provide free lunch for software, The software scalabilty actually turn to find out a way to eat up all of extra CPU speed , memory and storage space. People pursue to build a stronger and stronger application on a more and more powerful computer. Under the hood, the real driver in this way is Moorer's law. Although Moore's law is not over, it eventually will end someday. Without the free lunch, software should take action to save themselves.
Horizontal Scaling

Not like veritical scaling ride on free lunch, horizontal scaling intent to provide scalabilty via controlling machine count in the resources pool, ideally, we want to get a performance (near)linear increasing/reduction via add/reduce machines in the pool. To accomplish the goal, the software level need significant changes in fundamental layer, sometimes redesign also is involved to adopt to this approach.
Challenge of Horizontal Scaling
Ten years ago, I worked on a SOA product, which provides a standard way to encapsulate our implementation into component, we can declared a component by interface, and decoupled with it's implemnetation, and also provide easy way to expose as service via various transport/intraction protocols. This much reduce the complexity to build up a distrubted system. Later programmer find that when we use SOA to build up large application system, it ofen go to ESB(stands for Enterprise Service Bus) pattern, the ESB eventually grow up to the center of the system, it contain much major business logics, they are complex and finally become the most important point in the system, in the mean time, it become to the weak point in the system, since difficult to scale. To resolve this, we need to figure out way to setup a decentralized software architecture to fulfill the requirements.
Then micro-services architecture bring up. IMO, from pure techincal perspective, especially, in the service definition point of view, micro-services extends service concept in SOA, the key characteristics include:
- Restrict the service types
- Define the API gateway pattern with only non-functional requirements to avoid it grow up to ESB
- Stress on the isolation functionality of service delivery
- The micro-services also give suggestion on the team size, the "two-pizza" team rule implies team growing big will bring much communication efforts, which will finally slow down the development and hurt the efficiency.
All of these make the service independent enough for self-contained, which cover whole lifecycle of software deveopment, including: plan, definition, development, test, deployemnt, operations and sunsetting. Following the way, we can setup a decentralized system and split a large system into individual small services, each service run in separate process and be self-contained. This is great helpful to enable the system to be language-neutral, make each servcie small and focused, and choose best suited implementation statck, e.g: I/O-Bound, may select node.js and alternative java stack with Netty, CPU-intensive work may need Java, Golang or even C. These benefits make it possible to utilize the increated processing power to the fullest, and overcome the unbalance hardware development in CPU and I/O. Compare with monoliths, the micro-service apparently can highly reduce appliction complexity, but as a trade-off, it bring a high operational complexity, including devops, efficient runtime environment provision, service register, discover and job scheduler , and so on.
The CAP(stands for consistency, availability, and partition resistance) Principle states that it is not possible to build a distributed system that guarantees consistency, availability, and resistance to partitioning. Any one or two can be achieved but not all three simultaneously. For decetralized(partitioned) system, one more challenge is how to resolve consistency issue in our system, this previously was not a big problem in a monolithic application or a centralized system, as either the request handlers and replier are in same process, or a centralized node can act as decision maker to coordinate and provide a consistent result to caller, but now, we need to solve it from our software fundamental architecture to provide consistency behavior in a decentralized(partitions) network. This is big topic I do not want cover more details here. But in a short, different use cases can leverage different algorithms, typically we have two kinds of technical direction: ACID(Atomicity, Consistency, Isolation, Durability) and BASE(Basically Available, Soft-State, Eventually Consistent). The tranditional enterpise application which is bascially built upon centralized techonology, including: TX Management server, SQL and relational databases, they are using ACID to describe their CAP principles, and make sure the relevant actions run in a uow(Unit of Work), recently, some modern application isolate/break down the strong transaction requirement, and try to build up the system with small, lightweight and self-managed services, these services try to leverage the NoSQL database and(or) RESTful communication protocol to gain the benifits of decentralized/decoupled services and higher performance, which refer to BASE to describe their CAP principle. Generally, developing an application in BASE approach need to involve additional significant efforts in infrastructure and underlying persistence layer(e.g: implemented by a distributed consistency algorithm in the foundation layer), and also probably come to a specification in business contract interface to achieve this, e.g: implements TCC(stands for Try-Confirm/Cancel pattern) spec. The consistency and fault-tolerance become more difficult in a decentralized application, which sometimes also need to introduce a significant design consideration in fundamental layer to make this possible/easily. In a real-life practice, I do see many benifits in this area by involving data model design with a state + oplog pattern. For example, saying a e-wallet feature, a persistent state is the status on the account, e.g: balance for latest or a given condition(e.g: timestamp); oplog is the operations on the account, it is log style(data only can be added by appending mode following the busiess sequencing rule, e.g: timeline in this sample, neither update nor delete operation can work on this kind of data) data model pattern. The status are computed based on the oplogs at an appropriate time point you want, e.g: time of first-touch in a lazy-mode or the moment right after the oplogs get ready which offer as eager-mode. Furthermore, if need, we can replay the series of oplogs and get a eventually correct result/state. The oplog data actually takes two roles here, one is that it is the source input to compute state result, the other is it act on the proof data for recall and verification, in paruticular, the afterward auditor(either auto or manual) can understand failed transaction via a certain of relevant proof data, and figure out the break point, do either retry with continus-on-error-point or do compensations for wrongly commited parts. One more benifit is, if we have mixed-type services, e.g: some run in a on-premises environment, and others running in cloud, this kind of data design pattern could much recude the data replica complexity, and make it possible to make an incremental&continious data merge. The oplog-oriented data layer infrastructure(also a.k.a event sourcing ) is definitely a big topic, and I don't want to cover it in this series articles, maybe I can try to use a separate thread to elaborate this in more details.
Application Trend
The rapidly growing of the cloud confirms that more and more applications either being built upon cloud-native technology or start to do the cloud transformation. They build a large cluster with commodity hardware, enable application to scale on demand, manage their API over the time with pay-per-use model. The service clients interact with service provider hosted on cloud via different interaction fashion, including: tranditionally, the browser based application provide UI for human interaction, some native application may talk with the service via RPC style invocation(SOAP, Restful, gRPC and son on) to accomplish the message exchanging, some features such as collabration or instant message need involve long-lived connection, which may leverage web-socket to achieve, the p2p communication in web may involve WebRTC, etc. The web server play a key role in these invocations, we hope it has the capability of coping with increasing demand, and scaleable for large communications.
The web server built upon the network, it accept request from various clients and pass the response back. We know the I/O does not keep up with Moore's Law, furthermore, for network socket and pipe file sytle I/O, we actually can't expect the data always be ready for read in next CPU clock cycle, it depends on the user scenario and interaction style, the real-time message may triggered at an uncertain time point, latency is always there and unpredictable. On one hand, CPU is faster, on the other hand, network I/O is slow, some of scenario may have unpredictable latency. To have the webserver hardward resources get fully utilized, we need to have less processes to serve as much as possbile I/O operations, avoid to having I/O operation blocking the process, in such way to save the CPU time to serve more jobs. Using an async-style tech stack to handle requests should be a better choose in the I/O-intensive scenario. We will continue on this with more details in upcoming articles.
For the web server with CPU-intensive or long running operations, according to the CPU trend, the processor gain the performance by a multi-core manner, instead of increased clock cycle frequencies. This points us to the direction of making applications that are multi-threaded to better use the capabilities of the faster multi-core systems.
In different programming languages, Multi-process pattern could map to different implementation methods.
- Process, native OS process, have expensive context switch
- Thread, native OS thread, it essentially same as OS process, but share the same memory space, a faster create and swtich than process, but still have expensive context switch cost in the situation of concurrcy with rapid swtching.
- Some lightweight green thread scheduled by a optimal scheduler shipped by programming language, like goroutines in golang, it does not rely directly on OS kernel, many goroutines are multiplexed onto a single OS thread by Golang runtime, this make it much lightweight than native thread/process, event for the switch, tens of thousands of goroutines in a single process are the norm, hundreds of thousands are not unexpected.
Wrapping Up:
Moore's law are approching the end, it is time for us to review and redesign our application architecture to be decentralized and distributed, which is easy for horizontal scaling. The hardward development on I/O and CPU is unbalanced, I/O is slow. CPU trend tell us it does not become faster, but become wider, to make the hardware resources get fully utilized by our system, differernt modules in a system may need different tech-stack to implement/optimize. The micro-services architecture provide a guidance on splitting a large system into smaller services, we are in a transitional period of monolithic applications toward micro-services architecture, it provide more flexibilities to allow programmer to optimize the application in a fine-grained fashion. For each module/service, we can identify I/O-bound vs. CPU-bound, leverage appropriate programming languages, frameworks and libraries to implement such systems. With the cloud techology become popular rapidly, the modern applications heavily rely on a high scaleable/concurrency web server. Building an application server with high-performance I/O infrastructure is vital for a success project, which is required to stand strong and support the growth of keeping increased the numbers of transactions.
Some personal experiences, IMHO, if you are setting up I/O-bound system, Some event-loop based programming language(node.js, golang), framework(Netty with java stack), library(libuv, libev, libeio in C) might be better candidates for you.
Under the hood, golang use network poller to do the I/O operations, it actually perform the network I/O in non-blocking manner, but makes asbtraction on these, in such way to hide the event-loop internally and avoid introduce complex, callback driven style in it's programming model.
If you are facing CPU-bound service, Java, Go, even C are seen as go-to technology for you. For big-data, Python, Java and Scala should what you are looking for.
Any comments/correction is welcome
This article is Part 1 in a 3-Part Series.
- Part 1 - This Article
- Part 2 - Boost I/O Strategy - Dive into Libev and Libeio
- Part 3 - Boost I/O Strategy - The Internals of Libuvc